
培地成分を対象としたベイズ最適化の活用入門
はじめに
あらゆる
こうした
そこで
そんな
とは
そこで
細胞挙動を再現した関数の作成
先ほど
本稿では
ここでは、
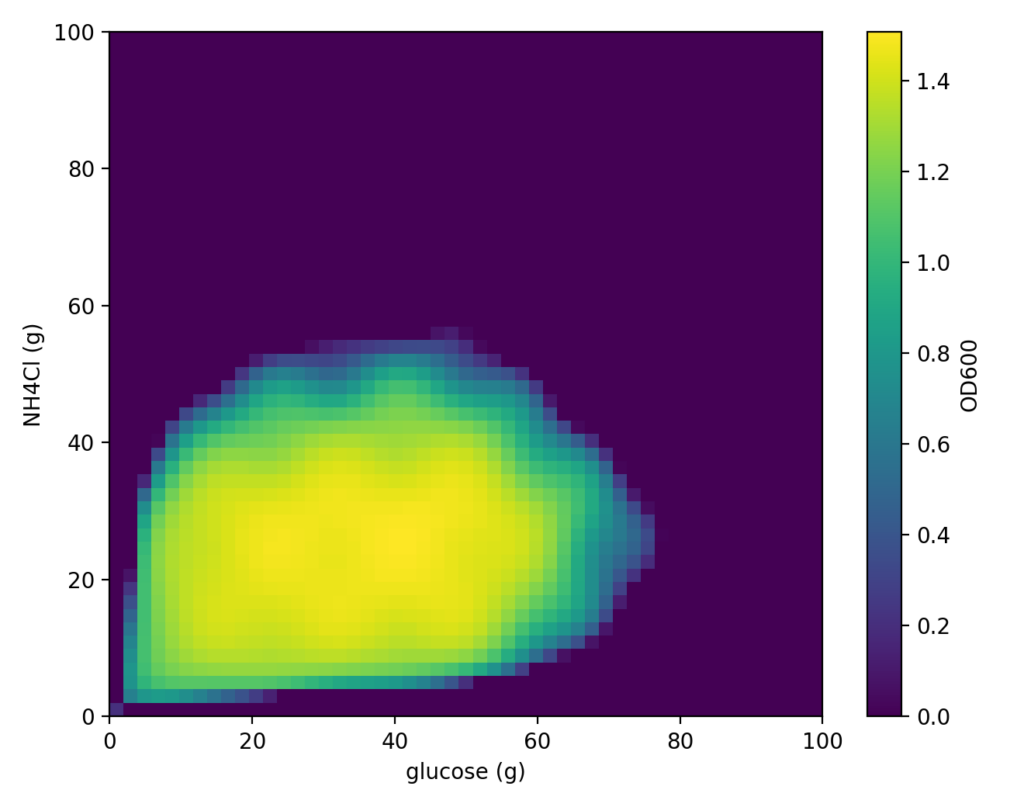
ベイズ最適化では、
- x = グルコース量
(g) - y = NH₄Cl量
(g)
実験条件
(5.0 g, 5.0 g), (5.0 g, 95.0 g), (95.0 g, 5.0 g), (95.0 g, 95.0 g), (50.0 g, 50.0 g)
この
| Glucose (g) | NH₄Cl (g) | OD₆₀₀ |
|---|---|---|
| 5.0 | 5.0 | 0.761678 |
| 5.0 | 95.0 | 0.874593 |
| 95.0 | 5.0 | 0.879424 |
| 95.0 | 95.0 | 0.902424 |
| 50.0 | 50.0 | 1.079207 |
以降の
![]()
まず
!pip -q install imageio openpyxl scikit-optimizeこの
import pandas as pd
from io import StringIO
csv_text = """Glucose (g),NH4Cl (g),0D600
5.0,5.0,1.079207
5.0,95.0,0.000000
95.0,5.0,0.000000
95.0,95.0,0.000000
50.0,50.0,0.510030
"""
# 文字列CSV → DataFrame
df_raw = pd.read_csv(StringIO(csv_text))
# 列名を標準化:x=glucose, y=NH4Cl, od=OD600
seed_df = df_raw.rename(columns={"Glucose (g)": "x", "NH4Cl (g)": "y", "0D600": "od"})
# 確認
seed_df読み込まれた
x y od
0 5.0 5.0 1.079207
1 5.0 95.0 0.000000
2 95.0 5.0 0.000000
3 95.0 95.0 0.000000
4 50.0 50.0 0.510030続いて、
from od_objective_2d import ODObjective2D, BOUNDS2D
from skopt import Optimizer
from skopt.space import Real
import numpy as np
# 目的関数(細胞くん)の生成
obj = ODObjective2D()
# 探索範囲(x=glucose, y=NH4Cl の下限/上限)を定義
space = [Real(BOUNDS2D["x"][0], BOUNDS2D["x"][1], name="x"),
Real(BOUNDS2D["y"][0], BOUNDS2D["y"][1], name="y")]
# ベイズ最適化器の生成
opt = Optimizer(
dimensions=space,
base_estimator="GP", # 内部の代理モデルにガウス過程 (Gaussian Process) を使用
acq_func="EI", # 獲得価値関数:改善期待値 (Expected Improvement) を使って「次に測るべき点」を決めます。
random_state=7
)
best_od = -np.inf
best_xy = (None, None)
rows = []
for i, r in seed_df.reset_index(drop=True).iterrows():
xi, yi, odi = float(r["x"]), float(r["y"]), float(r["od"])
opt.tell([xi, yi], -odi)
if odi > best_od:
best_od, best_xy = odi, (xi, yi)
rows.append({"iter": i+1, "phase": "seed", "x": xi, "y": yi, "od": odi,
"best_so_far": best_od, "best_x": best_xy[0], "best_y": best_xy[1]})ODObjective2Dは
Optimizer(...):ベイズ最適化器を
base_estimator="GP":内部の代理モデルにガウス過程 (Gaussian Process) を 使用。 acq_func="EI":改善期待値 (Expected Improvement) を使って 「次に 測るべき点」を 決めます。
ここまでで
n_iters = 20 # 実験の総回数
print("\n=== ベイズ最適化を開始(実験設計→実験→モデルに問い合わせ) ===")
for t in range(1, n_iters+1):
# 1) ask: 次に測るべき点を1つ提案
x_next, y_next = opt.ask()
print(f"[BO iter {t}] 提案点: Glucose={x_next:.3f}, NH4Cl={y_next:.3f}")
# 2) 実験(今回デモなので関数を呼ぶ。実運用ではここを実測に置換)
od_measured = float(obj(x_next, y_next))
print(f" 測定 OD= {od_measured:.6f}")
# 3) tell: 新しい観測を BO に渡す
opt.tell([x_next, y_next], -od_measured)
# 4) ベストの更新チェック
improved = ""
if od_measured > best_od:
best_od, best_xy = od_measured, (x_next, y_next)
improved = " ← ★ベスト更新!"
rows.append({
"iter": len(rows)+1, "phase": "bo",
"x": x_next, "y": y_next, "od": od_measured,
"best_so_far": best_od, "best_x": best_xy[0], "best_y": best_xy[1],
})
print(f" 現在のbest = {best_od:.6f} @ {best_xy}{improved}")n_itersは
この
=== ベイズ最適化を開始(実験設計→実験→モデルに問い合わせ) ===
[BO iter 1] 提案点: Glucose=22.734, NH4Cl=31.897
測定 OD= 1.421598
現在のbest = 1.421598 @ (22.733907982646524, 31.89722257734033) ← ★ベスト更新!
[BO iter 2] 提案点: Glucose=97.822, NH4Cl=45.558
測定 OD= 0.000000
現在のbest = 1.421598 @ (22.733907982646524, 31.89722257734033)
[BO iter 3] 提案点: Glucose=30.801, NH4Cl=26.387
測定 OD= 1.464924
現在のbest = 1.464924 @ (30.80127651877394, 26.387083903789872) ← ★ベスト更新!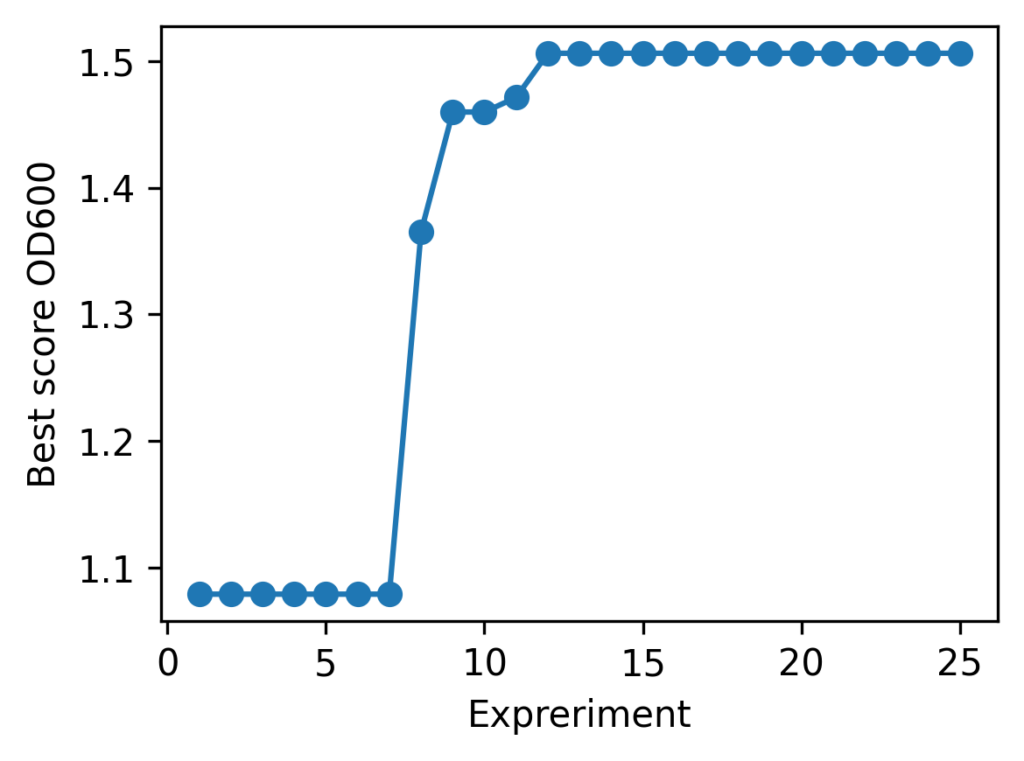
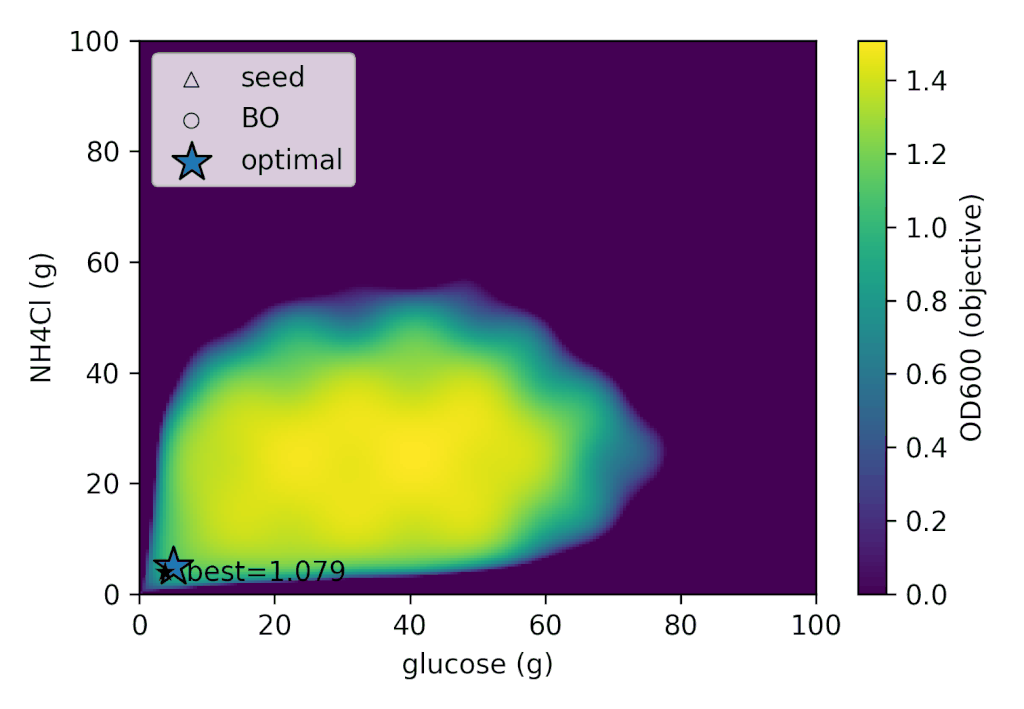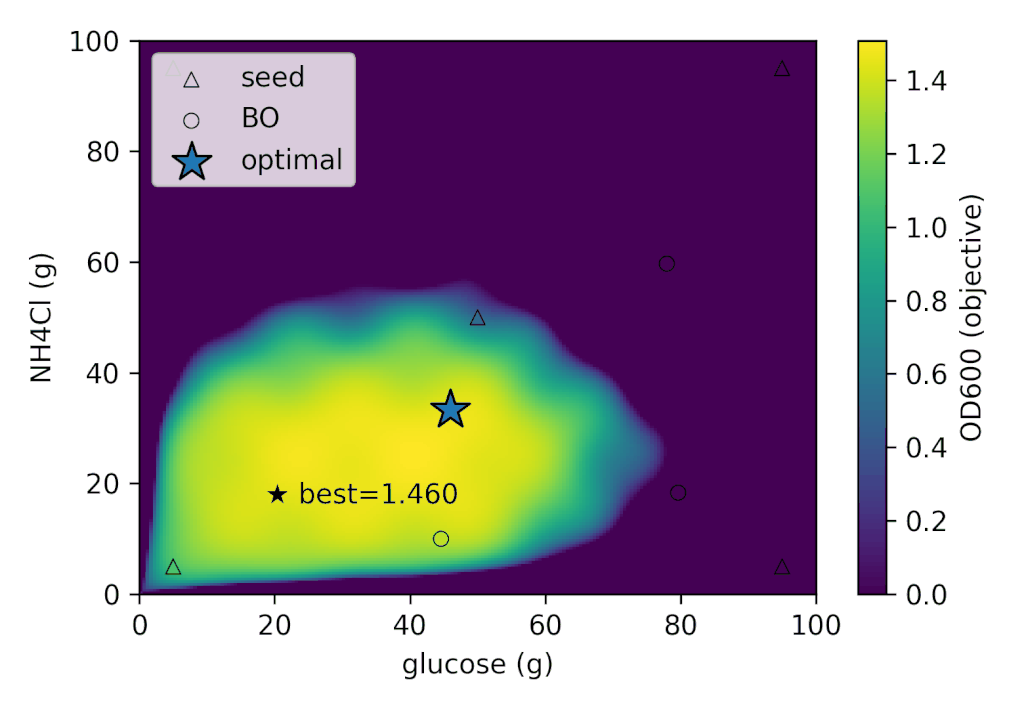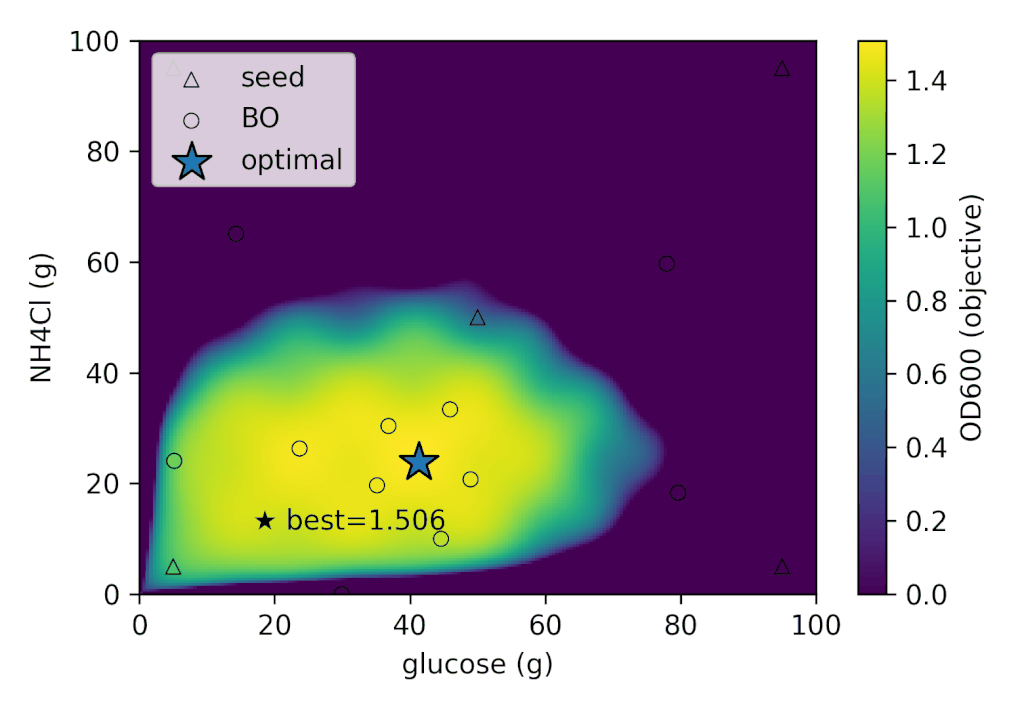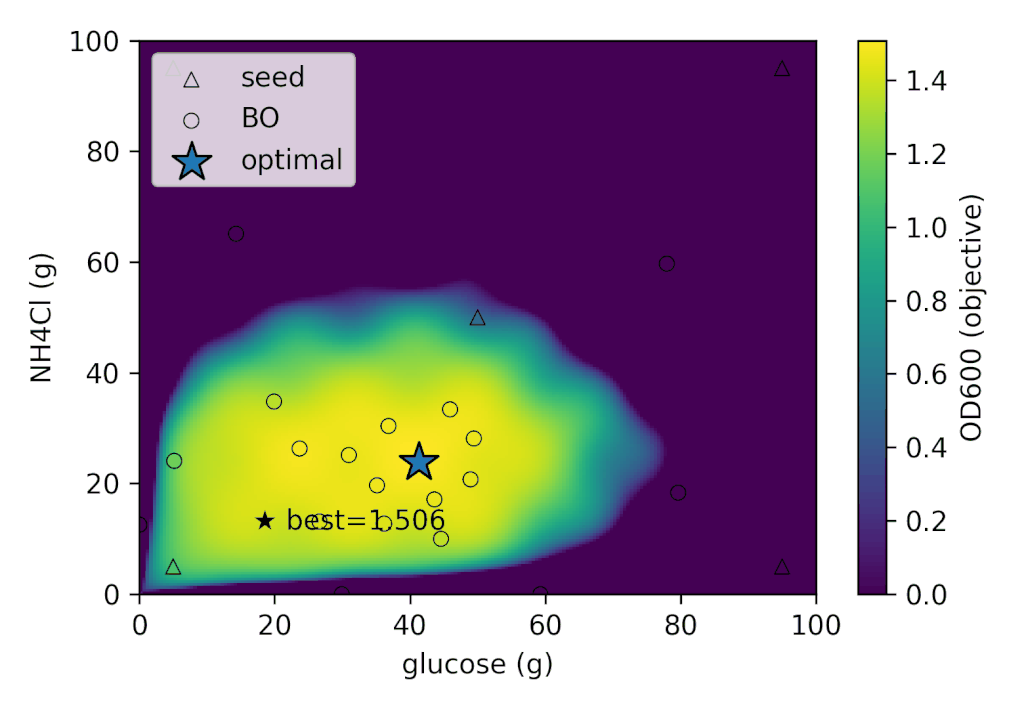
左: 各ラウンドごとの
今回の
| best_OD₆₀₀ | best_glucose (g) | best_NH₄Cl (g) |
|---|---|---|
| 1.505 | 41.280 | 26.775 |
と
このように、
今回は
今回の
(次回)
実行環境について
本ページ記載の
最終動作確
Python バージョン
Python 3.10.12
使用ライブラリのバージョン
| ライブラリ | バージョン |
|---|---|
| dataclasses | 0.6 |
| imageio | 2.37.0 |
| matplotlib | 3.10.0 |
| numpy | 2.0.2 |
| openpyxl | 3.1.5 |
| pandas | 2.2.2 |
| scikit-optimize | 0.10.2 |